
1. Introduction
learn by training available data sets to establish patterns in existing data and make predictions about new data (Hall et al., 2016). ML draws from various fields such as data mining, statistics, artificial
intelligence, analytics, and optimisation studies. Artificial intelligence(AI) is often regarded as the predecessor of machine learning (Marr,2016). More recently, the complexity of data generation and the quest to make machines assimilate human intelligence have pushed the boundaries of AI to construct intelligent machines that can learn independently of human input (Agavanakis et al., 2019). Since the inception of machine learning in the early 1950s, it has gained so much prominence. Its demand is expected to grow substantially due to increased data volume and variety. ML is now used in scientific, engineering, manufacturing, agricultural, commercial and social settings (Jordan & Mitchell,2015). The adaptability of machine learning algorithms facilitates the generation of insights from a variety of complex and very large data sets. This has promoted the adoption of machine learning across a variety of fields to generate necessary insights to support decision-making. In totality, Digital transformation is the driver of enormous changes which embeds integration of digital technology into business operations, processes, and management to deliver better, faster, and more comprehensive insights about a business, products, services, and customers with the aim of creating efficiencies and value for its customers and profit for the business (Müller, Junglas, Brocke & Debortoli, 2016; Grover, Chiang, Liang, & Zhang, 2018). Hence the investments in digital transformation initiatives are often driven by companies who want to retain or improve their competitive advantage. Hence it is no surprise that an increase in investments is predominantly driven by companies that want to keep up with the demand from their customers through insights such as those gained from Business Intelligence(BI) capabilities (Grover et al., 2018; & Müller, Kiel, & Voigt, 2018). However, as more corporate and academic research points to the benefits associated with the adoption and implementation of machine learning technologies by private businesses, there appears to be limited literature highlighting the issues, challenges, and impacts of implementing machine learning
technologies within the business context, specifically in the financial services sector( Hall et al., 2016; Arunachalam, Kumar, & Kawalek, 2018). The aim of this paper is to address the research gap from an
academic context by conducting a systematic literature review of the scholarly literature on the issues, challenges, and impacts of implementing machine learning in the financial services sector. The paper is arranged in the following manner: section 1 is the introduction, section 2 covers the literature review, section 3 delves into the research methodology, section 4 covers the research findings, and section 5 concludes the study.
1.1 Objective
The main aim of this paper is to uncover the extent to which machine learning has been researched in the context of the issues, challenges, and impacts of implementing ML in the financial services sector and to identify potential areas for future research. This will be achieved by exploring the different implementations of ML techniques in the financial services sector to identify, analyse and evaluate the issues, challenges, and impacts of implementing those machine learning models/techniques (Jordan & Mitchell, 2015).
1.2 Research questions
The primary research question that this study seeks to address is:
What are the issues, challenges and impacts of implementing Machine Learning in the financial services sector?
Sub-Questions:
• In what financial business contexts are ML technologies implemented?
• What ML methods/techniques are implemented in each financial business context?
2. Literature review
2.1 Applications of machine learning in the financial services sector
The financial services sector has long been using statistical techniques to analyse and mine various financial data from different sources to gain new insights such as valuing investments, assessing
customer creditworthiness and assessing risk. In recent times, the advancements in computing power, cheaper cloud storage, and demand to make more informed business decisions have invested in machine learning-driven technologies more common and influential within the financial services sector (Manlangit, Azam, Shanmugam, & Karim, 2019). According to Leo et al. (2019), implementing ML is
important, especially when financial services institutions require the necessary analytical capability, as the implementation is likely to impact every aspect of their business model. In certain financial services environments, unsupervised ML is often used to explore the complex input data from their clients’ loan records, where regression and classification methods are used to predict key credit risk variables to determine the risk of clients defaulting on loan payments (Khandani et al., 2010; Van Liebergen, 2017). However, one of the major challenges in financial institutions is the detection and prevention of credit card fraud. Credit card transactions, by design, produce very large datasets that require advanced algorithm training to detect complex patterns for the classification of fraudulent transactions from nonfraudulent ones and to detect potential money laundering transactions from normal transactions. Manlangit et al. (2019) applied ML techniques to transform the raw credit card transaction data into meaningful patterns, followed by K- Nearest Neighbours (k-NN) analysis to classify fraudulent transactions from non-fraudulent transactions. It was then concluded that their proposed technique improves the accuracy of detecting fraudulent transactions faster and more accurately than the conventional rule-based systems used by banks. This proves that innovative ways of combating credit card fraud are being investigated and are much needed due to the magnitude of the problem. In many instances, machine learning techniques are used in surveillance and monitoring for investment banks and securities exchange regulatory bodies to identify misconduct and trading breaches that result in
high financial and reputational costs. Evidence of studies is growing in understanding the application of various machine learning techniques to predict things such as bankruptcy of clients and businesses, as well as research into the use of ML methods to evaluate and assess risk in the banking sector(Leo et al., 2019; Qu, Quan, Lei, & Shi, 2019).
2.2 Related works and knowledge gaps
Due to the widespread use of machine learning, questions about the issues, challenges, and impacts of implementing machine learning in a business context are becoming more relevant and necessary to
be answered (Müller et al., 2016; Grover et al., 2018). According to a comprehensive literature review conducted by Trieu (2017) to evaluate the evidence published between 2000 to 2005 on the value
derived from BI systems by organisations, it is argued that although the impact of BI is significant, the conditions need to be favourable to an organisation to reap the benefits of implementing a BI system as some of the internal and external factors that may hinder the value realisation by an organisation (Trieu, 2017). Since the review focused on literature between 2000 and 2005, it was highlighted that there was a lack of studies looking into how BI impacted the internal and external factors to create business value. It was then rec-ommended that such studies should be conducted. In another systematic literature review between 2000 and 2017 exploring BI in Small and Medium-sized Enterprises (SMEs) the implementation of BI presented a new set of challenges that could potentially hinder the realisation of the benefits of implementing BI by SMEs (Llave, 2017). Challenges such as the lack of established frameworks and standards guiding the governance, security, and guarantee of privacy when utilising BI technologies were identified.
Both systematic literature reviews highlight an adequate body of evidence on implementing BI technologies in some business sectors and the resultant challenges associated with these technologies.
However, neither of the reviews was primarily focused on ML, nor did they highlight challenges, issues, or impacts that are specifically associated with or as a result of machine learning in particular. In another study, Devi and Radhika (2018) compared various statistical and ML techniques by evaluating their performance ratios, including accuracy, specificity, sensitivity, and precision in detecting and predicting bankruptcy. Some notable benefits identified in the study include the finding that ML techniques have better performance accuracy. However, their discussion of limitations is limited to the inherent technical applicability of various methods and their performance and not so much to the impact or challenges presented to the broader financial services sector due to the implementation of these ML techniques. Similar reviews evaluating the applicability and performance of various statistical and ML techniques in bankruptcy prediction have been conducted (Lin et al., 2011; Qu et al., 2019). Similarly, they both fall short of discussing the overall impact or challenges of implementing ML techniques in the business models of the broader financial services sector. Leo et al. (2019) reviewed literature that evaluates and discusses ML techniques that have been researched in the context of risk management in the banking sector but have yet to delve into broader ML issues in the financial sector.
Van Liebergen (2017) discusses the application of ML in the area of credit risk modelling and comes to conclude that non-parametric and non-linear ML methods are too complex to understand and audit,
which is to the displeasure of most financial supervisors who typically require models to be clear and simple to understand, verify and validate. Regulations around data sharing and data usage were also
identified as key impediments to achieving the data capacity to make meaningful interpretations and conclusions about the data analysed. As such, there remains a knowledge gap about the comprehensive
documentation of the issues, challenges, and impacts of implementing ML in business, particularly in the financial services sector.
3. Methodology
This systematic literature was conducted by following the guidelines by Hagen-Zanker & Mallett (2013) on conducting a qualitative systematic literature review in the field of information systems. A description of search criteria and terms used for identified databases, the inclusion and exclusion criteria, the bias identified, and the data extraction and thematic analysis of the evidence. To answer the research questions outlined in section 1.2, a qualitative research approach in the form
of a systematic literature review, as depicted in the PRISMA flowchart in Figure 1, was adopted.
Scholarly literature published from 2013 to 2022 from the following databases: Science Direct,ProQuest and Ebsco Host were consulted. Instead of consulting one source, three sources were chosen to minimise bias by choosing databases containing various relevant and current literature on ML studies. The systematic literature review method has been used in different disciplines and relied upon for issues
identification for future research. The PRISMA diagram in Figure 1 summarises the steps taken to conduct the systematic literature review. The inclusion and exclusion criteria are detailed in Table 1.
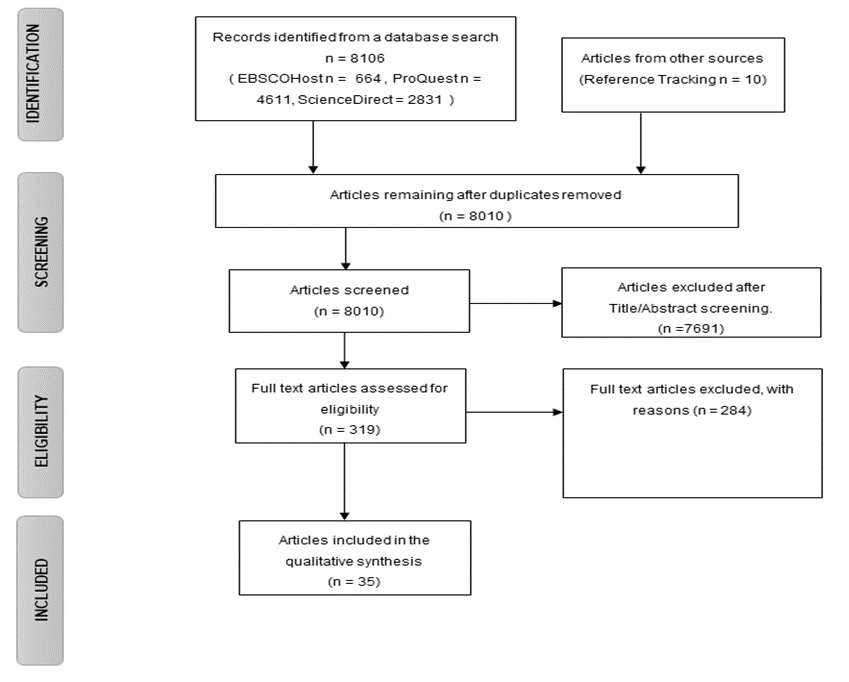
Figure 1: PRISMA
The following section explains the activities in the stages contained in Figure. 1: These stages were guided by the inclusion and exclusion criteria for the literature survey, as outlined in Table 1
The literature review was conducted using the academic institution’s library resources where the researchers are affiliated. The literature search was conducted in September 2020 and December 2022.
Only the literature that was available and accessible from the chosen databases on the date of the search was used.
Following the adapted PRISMA flow chart outlined in Figure.1, the following steps were carried out during the systematic literature review.
Identification phase
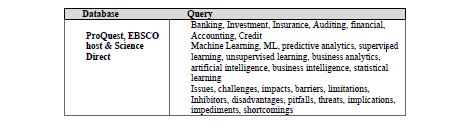
After selecting the following database sources, i.e. EBSCO Host, Science Direct and ProQuest, the relevant literature was selected using the keywords/phrases in Table 2.
Table 2: Keywords and Database Search Terms
The initial search results yielded 8106 records in total from the three database sources. After duplicate removal,8010 articles remained for further review.
Screening Phase
The 8010 articles were reviewed based on the content of their abstracts and titles. From that review, 7691 articles were excluded after the title and abstract review, and 319 articles remained for further analysis.
Eligibility
A detailed analysis of the 319 articles was further done, and 284 articles were excluded as they were found irrelevant. Thirty-five articles were found suitable for further review and analysis to solicit the answers to address the research questions posed for this study.
Synthesis
In total, 35 articles were synthesised to obtain answers to the research questions, as outlined in section 1.2.
3.1 Bias identified and addressed
To minimise bias in this study, measures were taken to address bias in the following manner: In addressing location bias which comes as a result of restricting search limiters or sources which can potentially ignore a relevant body of evidence (Keenan, 2018), sources from published sources and grey literature were consulted to have a representative balanced collection of evidence (Drucker,
Fleming, & Chan, 2016; Keenan, 2018). Evidence Selection Bias: is often introduced when a study fails to equitably identify all available unclear sources, which can be due to unclear definitions of key topic
concepts (Drucker et al., 2016; Keenan, 2018;). To address this, the steps outlined in Figure 1 were followed within the inclusion and exclusion criteria confines. Synthesis / Reporting Bias-This form of bias can arise when researchers selectively report some findings and exclude others (Drucker et al., 2016). This was addressed by making use of the inclusion criteria designed for this study. Competing Bias usually arises when funding was obtained to support the study, and there is some connection with the funded entity(Drucker et al.,2016). The researchers have no conflict of interest in relation to this study.
3.2 Data analysis
Data were extracted from the 35 remaining articles for qualitative synthesis and put into an analysis matrix, and thereafter, thematic analysis was applied as this is commensurate with qualitative studies
of this nature. Thematic analysis is a technique generally used to identify, analyse, organize, and report data in themes in a specific data set (Roberts, Dowell, & Nie, 2019). As this systematic literature review aimed to qualitatively review the issues, impacts, and challenges of implementing ML in the financial service sector, a six-phase step practical guide on conducting a reliable thematic analysis was adopted(Nowell et al., 2017). The first step was concerned with getting the researchers familiar with their research area to stimulate their thoughts and get them to start asking the right and relevant questions. The codes for the financial sector identified, models, implemented, and identified challenges were generated in the second phase to simplify and ensure focus on the research questions (Nowell et al., 2017; Roberts et al., 2019). The third phase was concerned with searching for themes which only starts once all coded data
extracts are collated into meaningful sub-themes (Nowell et al., 2017). In the third phase, the review of the set of themes devised is conducted to check for the validity and meaning of patterns. It is in this phase that errors in the initial coding start to emerge (Nowell et al., 2017), and where errors may start to converge or diverge. In this study, based on the outcome of the literature review, the identified challenges code was broken into two codes, the intrinsic challenges and extrinsic challenges to make sense of challenges that are intrinsic to the model and those that are as a result of the sector(extrinsic). The second last phase was concerned with the labelling of the themes based on the aspect of the data each theme captures and the overarching link it makes with the research focus and research questions. This was done to ensure alignment that all the developed themes are linked to the global organizing theme of the issues, impacts, and challenges of implementing ML techniques in the different financial services activities. The last and final step was for the researchers to verify that they had captured all the themes and thus could start with the final analysis and proceed with the write-up. The codes identified and the themes are depicted in Figure 4.
4. Findings
Following the literature search conducted by ProQuest,Ebsco Host and Science Direct, using the chosen keyword strings, only 35 articles remained for synthesis as those articles fully satisfied the inclusion criteria in Table 1. Figure 2 depicts the number of articles in the financial services sector. According to the information in Figure 2, most of the articles were on challenges regarding using ML in the financial services sector, focusing on Bankruptcy prediction, followed by fraud detection. This was followed by credit default prediction, forecasting of the stock market performance and general use, penultimate, and the least of the sources focused on risk management.
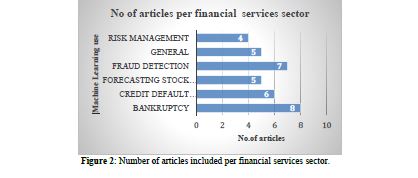
Figure 3:shows the common machine learning models per financial services sector, with the hybrid or ensemble model commonly used in Bankruptcy prediction and credit default prediction. Deep learning and neural networks are commonly used in risk management.
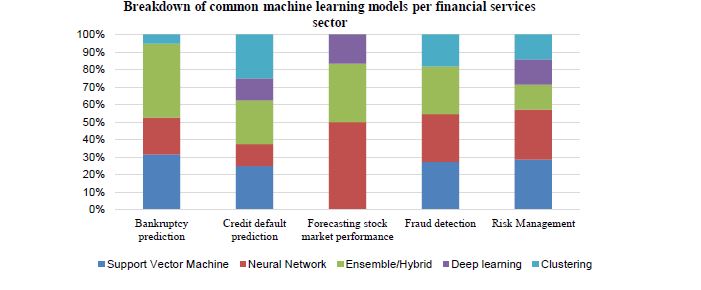
Figure 3: Common machine learning models per financial institution
4.1 Machine language uses in the financial services sector
4.1.1 Bankruptcy
Financial institutions, especially banks and credit bureau agencies, use machine learning to predict bankruptcy for their clients. Predicting bankruptcy assists financial institutions in preventing financial losses through the granting of loans to risky entities. Support Vector Machine (SVM) is generally used as a starting point for bankruptcy prediction; however, due to their limitation in handling large complex data, hybrid and ensemble models are often used because of their superiority when it comes to predictive accuracies (Xie et al., 2013; Lu et al., 2015).
4.1.2 Fraud prediction
Different crimes are committed for financial gain, such as tax evasion and money laundering. Money laundering is one of the main challenges banks seek to address. The ability to accurately identify
fraudulent activities or predict fraudulent activities is what ML offers as a solution to reduce the occurrence of fraudulent activities which affect the banks. According to Chen et al. (2018), the identification of fraudulent activities is not a simple task since, in reality, there are fewer fraudulent transactions than fraudulent ones, and the identification of fraudulent activities requires going through large volumes of transactions, particularly for SVM. It is argued that the complexity of transactions data makes SVM to poorly perform, and it makes ANN very difficult to implement due to poor data quality issues (Chen et al. 2018;Aslam et al., 2022; Roseline et al., 2022; Lokanan & Sharma, 2022;Aslam et al., 2022;Canhoto, 2021). Moreover, the unavailability and poor data quality due to compounding changes in transaction behaviour make ensembles and deep learning perform poorly. The risk of false positives is also high, which threatens banks as they stand to annoy customers(Khang et
al., 2021) by constantly erroneously flagging them.
4.1.3 Credit Default Prediction
Knowing the credit score and default prediction is paramount for organisations in the financial services sector as they need to accurately determine which clients will be able to repay their loans so
that they only loan to clients with satisfactory credit scores or records. Financial service institutions rely on accurate and efficient credit default prediction for the profitability and operations of their institutions. According to Shi & Xu, 2016; Moula, Guotai, & Abedin;2017 & Liu et.al,2022, the ability to accurately predict whether credit applicants will be able to pay back the money is a key to determining how much to loan them. Customer data quality issues (Twala,2013) make it difficult to rely on some of the ML models because of the risk of inaccurate decisions.
4.1.4 Forecasting stock market performance
Machine learning is also used to predict stock market movements and assist potential buyers in deciding on when to buy stock or commodity and when to sell. This decision is also essential for fund
managers, stockbrokers and investment analysts at large (Kraus & Feuerriegel, 2017; Sigo, Selvam, Venkateswar, & Kathiravan, 2019). The data in stock market conditions are highly volatile; as a result
accurate prediction is required to accommodate the volatility. The ML models often implemented for such purposes are often Artificial Neural Network (ANN), Ensemble, and deep learning (Kraus &
Feuerriegel, 2017; Sigo et al., 2019). However, the accuracy of these models is negatively affected by unpredictable situations such as stock price volatility. In addition, the technical analysis models exclude factors such as regional politics and transaction costs.
4.1.5 Risk management
The financial services sector faces many challenges which include the implementation of new technological solutions such as ML and how it affects its processes and the way to comply with regulations. When it comes to fraud prediction, accuracy of flagging the exceptions is pivotal as resources are dedicated to investigating the suspected fraudulent transactions. Incorrect identification of fraudulent transactions could result in wasteful expenditure and resources (Zhang et al., 2021). Hence financial institutions need to conduct risk assessments to determine if ML is successfully implemented in an organisation or not before they can extend its scope. The ML models especially the predictive ones (Horak et al. 2020) are not perceived to be perfect as they may omit certain indicators such as risky
decisions and unfavourable business markets. ML techniques are also used for other uses which can be regarded as general use such as house prices prediction((Forys,2022) and airline prices prediction (Vadlamani et.al,2022). In such instances a hybrid of models may be applied to reach desirable outcomes.
According to Mahalakshmi et al.,( 2022), ML and AI are commonly used in the financial sector in document analysis (Mahalakshmi et al., 2022); of which in our study falls under the general use as there are various documents which can be analysed for different purposes.
Based on the outcome of the analysis, it was found that most of the evidence focuses more on the internal ML implementation but is not necessarily specific on the impact it has on the specific sector where ML is applied. The remainder of the literature found is in the form of evidence which focuses a lot more on the challenges of applying ML, which is not business model specific. The challenges were grouped into six thematic themes, as depicted in Figure 4, which were aligned to the ML models. These themes were merged into one all encompassing general theme: The research into the implementation
of machine learning models is still very academic and focused on the intrinsic challenges of individual models than their impact on the sector, such as regulation, transparency, and skills shortage. The general theme was to address the research question, which asks: What are the issues, challenges and impacts of implementing Machine learning in each financial business context?
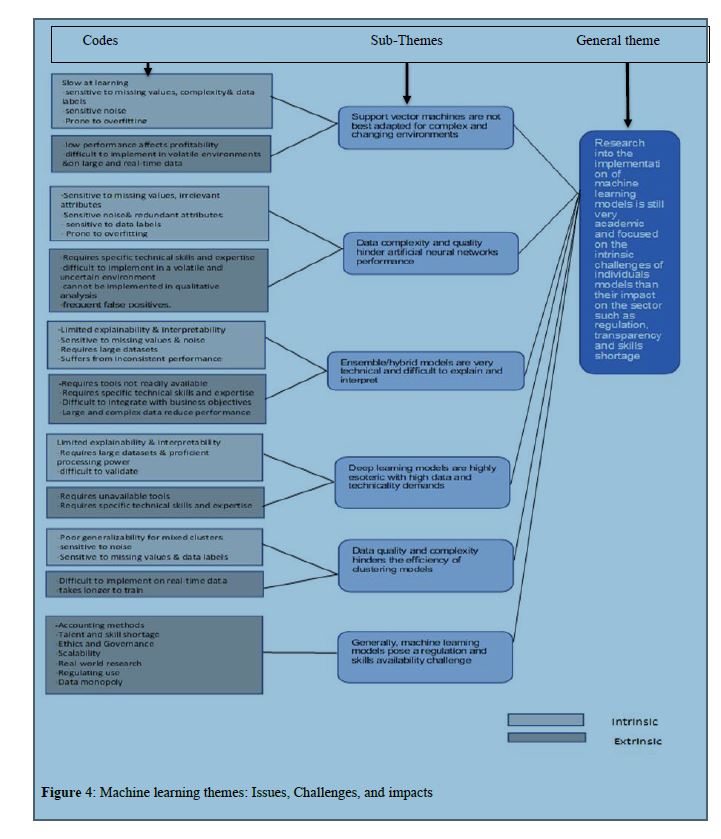
Figure 4: Machine learning themes: Issues, Challenges, and impacts
Figure 4 outlines the six themes identified, with five clusters of codes associated with the intrinsic challenges of each model and six extrinsic or systemic challenges due to ML implementation. For each
ML model, we combined the codes into sub-themes.
The six themes that emerged are as follows:
The six themes that emerged are as follows:
• Support vector machines are not very suitable to implement for complex and changing environments.
The issues around the implementation of SVM are of handling the missing data values and the noise and sensitivity to data labels. The SVMs seem ideal for performance in more static
environments.
• The complexity of data and quality issues hinder artificial neural networks performance.
Data is fundamental in generating relevant insights in the financial context, however, the sensitivity to noise, data labels and redundant attributes often temper the optimum performance of artificial neural networks.
• Ensemble/hybrid models are often technical and cumbersome to explain and interpret.
In performing certain types of calculations, hybrid models are often used to strengthen the functioning of the models to achieve the desired outcomes. However, when it comes to ensemble/ hybrid models, the primary concern is that these models require specific technical skills to implement. A financial institution will thus need to invest on the acquisition or training of resources who will successfully implement or operationalise these models. From a productivity perspective, ML and AI have been seen to enhance employee productivity or work outcomes in organisations (Ramachandran et al., 2022).
• Deep learning models are highly esoteric with high data and technicality demands
The implementation of deep learning models also required the use of resources with the relevant technical skills. From a functionality perspective, the implementation may also require the use of tools which may not be readily available.
• Data quality and complexity hinders the efficiency of clustering models
Clustering models are also sensitive to noise, missing values and data labels. They may also be difficult to implement in a changing environment.
• Generally, machine learning models pose a regulation and skills availability challenge.
Machine learning methods pose a challenge with respect to the skills that are required to implement these models and the ability to regulate the use of ML as the scope of use often require the use of personal information which pose a challenge from an ethics and governance point of view. It remains a challenge on how the evolution and implementation of ML can be implemented.
Lastly, the six sub-themes were merged into a single general and all-encompassing theme which states that “research into the implementation of machine learning models is still very academic and focused on the intrinsic challenges of individuals models than their impact on the sector such as regulation, transparency, and skills shortage. The general theme was to address the question by
encapsulating the answer to the main research question.
5.Conclusion
The study aimed to understand the different business contexts within the financial services sector where ML techniques are implemented. It was found machine learning is predominantly implemented in bankruptcy prediction, followed by credit default prediction, forecasting of stock market performance, fraud detection, and risk management. The ML methods/techniques that were generally implemented in financial sectors include highly complex artificial neural networks and ensemble models, which are the most implemented models across all sectors, followed by support vector machines, clustering, and deep learning techniques. Numerous issues, challenges and impacts were
identified in Figure 4. They are mainly concerned with the performance of ML, which is linked to the quality of the data that is used and the complexity of the calculations which are performed. The more complex the ML model is, the more likely the complexity of the analysis will be. Prediction inefficiency and inaccuracy can negatively impact the financial institution’s operations, finances, and overall
reputation; hence it is essential that risk management is done when implementing ML. Overall, Machine learning research is still very academic and focused on the intrinsic challenges of individual models
than their impact on the sector, such as regulation, transparency, and skills shortage. The study was limited in the sense that only specific keywords strings were used, three database sources were consulted, and if the scope was widened, it could have resulted in deeper insights. In addition, future research can look at specific external challenges of implementing ML, such as operational, adoption & skill shortage.
REFERENCES
Agavanakis, K. N., Karpetas, George. E., Taylor, M., Pappa, E., Michail, C. M., Filos, J., Trachana, V., & Kontopoulou, L. (2019). Practical machine learning based on cloud computing resources. AIP Conference Proceedings, 2123(1), 020096–1. asn. Software Engineering (pp. 3-4). ACM.
Akter, S., & Wamba, S. F. (2016). Big data analytics in E-commerce: A systematic review and agenda for future research. Electronic Markets, 26(2), 173–194.Retrieved from https://doi.org/10.1007/s12525-016-0219-0
Aslam, F., Hunjra, A. I., Ftiti, Z., Louhichi, W., & Shams, T. (2022). Insurance fraud detection: Evidence from artificial intelligence and machine learning. Research in International Business and Finance, 62.Retrieved from https://doi.org/10.1016/j.ribaf.2022.101744
Arunachalam, D., Kumar, N., & Kawalek, J. P. (2018). Understanding big data analytics capabilities in supply chain management: Unravelling the issues, challenges and implications for practice.
Transportation Research Part E: Logistics and Transportation Review, 114, 416–436. Retrieved from https://doi.org/10.1016/j.tre.2017.04.001
Bettany-Saltikov, J. (2010). Learning zone. Learning how to undertake a systematic review: Part 2. Nursing Standard, 24(51).
Canhoto, A. I. (2021). Leveraging machine learning in the global fight against money laundering and terrorism financing: An affordances perspective. Journal of Business Research, 131, 441–452.
Retrieved from https://doi.org/10.1016/j.jbusres.2020.10.012
Chen, Z., Van Khoa, L. D., Teoh, E. N., Nazir, A., Karuppiah, E. K., & Lam, K. S. (2018). Machine learning techniques for anti-money laundering (AML) solutions in suspicious transaction detection: A
review- Knowledge and Information Systems, 57(2), 245–285.
Devi, S. S., & Radhika, Y. (2018). A survey on machine learning and statistical techniques in bankruptcy prediction. International Journal of Machine Learning and Computing, 8(2), 133–139.
Drucker, A. M., Fleming, P., & Chan, A.-W. (2016). Research Techniques Made Simple: Assessing Risk of Bias in Systematic Reviews. Journal of Investigative Dermatology, 136(11), e109–e114.Retrieved from https://doi.org/10.1016/j.jid.2016.08.021
Du Jardin, P. (2019). Forecasting bankruptcy using biclustering and neural network-based ensembles. Annals of Operations Research, 1–36.
Foryś, I. (2022).Machine learning in house price analysis: regression models versus neural networks. Procedia Computer Science, 207, 435–445.Retrieved from https://doi.org/10.1016/j.procs.2022.09.078
Grover, V., Chiang, R. H. L., Liang, T.-P., & Zhang, D. (2018). Creating Strategic Business Value from Big Data Analytics: A Research Framework. Journal of Management Information Systems, 35(2), 388–423.Retrieved from https://doi.org/10.1080/07421222.2018.1451951
Hagen-Zanker, J., & Mallett, R. (2013). How to do a rigorous, evidence-focused literature review in international development: A guidance note. London: Overseas Development Institute.
Hall, P., Phan, W., & Whitson, K. (2016). The Evolution of Analytics: Opportunities and Challenges for Machine Learning in Business.O’Reilly. Retrieved from https://www.sas.com/content/dam/SAS/en_us/doc/whitepaper2/evolution-of-analytics-108240.pdf
Horak, J., Vrbka, J., & Suler, P. (2020). Support Vector Machine Methods and Artificial Neural Networks Used for the Development of Bankruptcy Prediction Models and their Comparison. Journal of Risk and Financial Management, 13(3), 60.
Jordan, M. I., & Mitchell, T. M. (2015). Machine learning: Trends, perspectives, and prospects. Science, 349(6245), 255–260. Retrieved from https://doi.org/10.1126/science.aaa8415
Keenan, C. (2018, April 18). Assessing and addressing bias in systematic reviews. Meta-Evidence.Retrieved from http://meta evidence.co.uk/assessing-and-addressing-bias-in-systematic reviews/Khandani, A. E., Kim, A. J., & Lo, A. W. (2010). Consumer credit-risk models via machine-learning algorithms. Journal of Banking & Finance, 34(11), 2767–2787.
Kitchenham, B. (2004). Procedures for performing systematic reviews. Keele, UK, Keele University, 33(2004), 1–26.
Kraus, M., & Feuerriegel, S. (2017). Decision support from financial disclosures with deep neural networks and transfer learning. Decision Support Systems, 104, 38–48. bsu.
Khang, P. Q., Kaczmarczyk, K., Tutak, P., Golec, P., Kuziak, K., Depczynski, R., Hernes, M., & Rot, A. (2021). Machine learning for liquidity prediction on Vietnamese stock market. Procedia Computer Science, 192, 3590–3597. Retrieved from https://doi.org/10.1016/j.procs.2021.09.132
Lagasio, V., Pampurini, F., Pezzola, A., & Quaranta, A. G. (2022). Assessing bank default determinants via machine learning. Information Sciences, 618, 87–97. Retrieved from https://doi.org/10.1016/j.ins.2022.10.128
Liu, Y., Yang, M., Wang, Y., Li, Y., & Xiong, T. (2022). Applying machine learning algorithms to predict default probability in the online credit market: Evidence from China. International Review of Financial Analysis, 79. Retrieved from https://doi.org/10.1016/j.irfa.2021.101971
Lokanan, M. E., & Sharma, K. (2022). Fraud prediction using machine learning: The case of investment advisors in Canada. Machine Learning with Applications, 8, 100269.Retrieved from https://doi.org/10.1016/j.mlwa.2022.100269
Leo, M., Sharma, S., & Maddulety, K. (2019). Machine learning in banking risk management: A literature review. Risks, 7(1), 1–22.
Lin, W.-Y., Hu, Y.-H., & Tsai, C.-F. (2011). Machine learning in financial crisis prediction: A survey. IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews), 42(4), 421–436.
Llave, M. R. (2017). Business Intelligence and Analytics in Small and Medium-sized Enterprises: A Systematic Literature Review. CENTERIS 2017-International Conference on Enterprise Information Systems/ Projman 2017. Retrieved from https://doi.org/10.1016/j.procs.2017.11.027
Lu, Y., Zeng, N., Liu, X., & Yi, S. (2015). A New Hybrid Algorithm for Bankruptcy Prediction Using Switching Particle Swarm Optimization and Support Vector Machines. Discrete Dynamics in Nature and Society, 2015. Computer Science Database; Middle East & Africa Database; Publicly Available Content Database. Retrieved from https://doi.org/10.1155/2015/294930
Mahalakshmi, V., Kulkarni, N., Pradeep Kumar, K. v., Suresh Kumar, K., Nidhi Sree, D., & Durga, S. (2022). The Role of implementing Artificial Intelligence and Machine Learning Technologies in the financial services Industry for creating Competitive Intelligence. Materials Today: Proceedings, 56, 2252–2255. Retrieved from https://doi.org/10.1016/j.matpr.2021.11.577
Manlangit, S., Azam, S., Shanmugam, B., & Karim, A. (2019). Novel Machine Learning Approach for Analyzing Anonymous Credit Card Fraud Patterns. International Journal of Electronic Commerce
Studies, 10(2), 175–201. bsu.
Marr, B. (2016). What Is The Difference Between Artificial Intelligence And Machine Learning? Forbes.Retrieved from https://www.forbes.com/sites/bernardmarr/2016/12/06/what-is-the-differencebetween-artificial-intelligence-and-machine-learning/
Moula, F. E., Chi Guotai, & Abedin, M. Z. (2017). Credit default prediction modeling: An application of support vector machine. Risk Management, 19(2), 158–187.
Müller, J. M., Kiel, D., & Voigt, K.-I. (2018). What drives the implementation of Industry 4.0? The role of opportunities and challenges in the context of sustainability. Sustainability, 10(1), 247.
Müller, O., Junglas, I., Brocke, J. vom, & Debortoli, S. (2016). Utilizing big data analytics for information systems research: Challenges, promises and guidelines. European Journal of Information Systems, 25(4), 289–302. Nowell, L. S., Norris, J. M., White, D. E., & Moules, N. J. (2017). Thematic Analysis: Striving to Meet the Trustworthiness Criteria. International Journal of Qualitative Methods, 16, 1–13.Okoli, C. (2015). A guide to conducting a standalone systematic literature review. Communications of the Association for Information Systems, 37(1), 43.
Qu, Y., Quan, P., Lei, M., & Shi, Y. (2019). Review of bankruptcy prediction using machine learning and deep learning techniques. Procedia Computer Science, 162, 895–899.
Ramachandran, K. K., Apsara Saleth Mary, A., Hawladar, S., Asokk, D., Bhaskar, B., & Pitroda, J. R. (2022). Machine learning and role of artificial intelligence in optimizing work performance and employee behavior. Materials Today: Proceedings, 51, 2327–2331. Retrieved from
https://doi.org/10.1016/j.matpr.2021.11.544
Roberts, K., Dowell, A., & Nie, J.-B. (2019). Attempting rigour and replicability in thematic analysis of qualitative research data; a case study of codebook development. BMC Medical Research
Methodology, 19(1), 1–8. Shi, J., & Xu, B. (2016). Credit Scoring by Fuzzy Support Vector Machines with a Novel Membership Function. Journal of Risk and Financial Management, 9(4).
Sigo, M. O., Selvam, M., Venkateswar, S., & Kathiravan, C. (2019). Application of Ensemble Machine Learning in the Predictive Data Analytics of Indian Stock Market. Webology, 16(2), 128–150.
Middle East & Africa Database.
Trieu, V.-H. (2017). Getting value from Business Intelligence systems: A review and research agenda. Decision Support Systems, 93, 111–124. bsu.
Twala, B. (2013). Impact of noise on credit risk prediction: Does data quality really matter? Intelligent Data Analysis, 17(6), 1115–1134. asn.
Van Liebergen, B. (2017). Machine learning: A revolution in risk management and compliance? Journal of Financial Transformation, 45, 60–67.
Xie, G., Zhao, Y., Jiang, M., & Zhang, N. (2013). A Novel Ensemble Learning Approach for Corporate Financial Distress Forecasting in Fashion and Textiles Supply Chains. Mathematical Problems in Engineering, 2013. Computer Science Database; Middle East & Africa Database; Publicly Available Content Database. Retrieved from https://doi.org/10.1155/2013/493931.
Yao, J., Wang, Z., Wang, L., Zhang, Z., Jiang, H., & Yan, S. (2022). A hybrid model with novel feature selection method and enhanced voting method for credit scoring. Journal of Intelligent and Fuzzy Systems, 42(3), 2565–2579.Retrieved from https://doi.org/10.3233/JIFS-211828
Zhang, C., Li, M., & Li, Y. (2021). Financial risk analysis of real estate bubble based on machine learning and factor analysis model. Journal of Intelligent and Fuzzy Systems, 40(4), 6493–6504.
Retrieved from https://doi.org/10.3233/JIFS-189488. Vadlamani, S. L., Shafiq, M. O., & Baysal, O. (2022). Using machine learning to analyze and predict entry patterns of low-cost airlines:A study of Southwest Airlines. Machine Learning with Applications, 10, 100410.Retrieved from https://doi.org/10.1016/j.mlwa.2022.100410